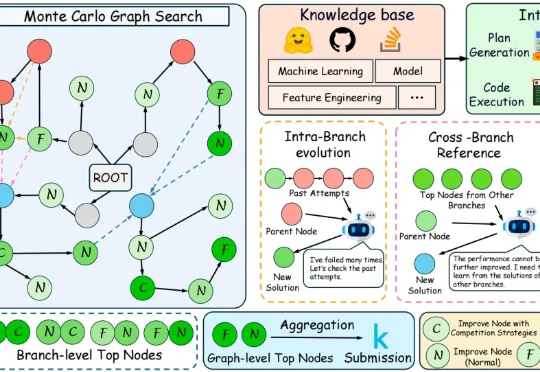
AI智能编程新框架,节省一半时间就能“聪明”地写代码丨上海AI Lab&华师大
AI智能编程新框架,节省一半时间就能“聪明”地写代码丨上海AI Lab&华师大在代码层面,大语言模型已经能够写出正确而优雅的程序。但在机器学习工程场景中,它离真正“打赢比赛”仍有不小差距。
来自主题: AI技术研报
9488 点击 2025-10-19 12:10
 搜索
搜索
在代码层面,大语言模型已经能够写出正确而优雅的程序。但在机器学习工程场景中,它离真正“打赢比赛”仍有不小差距。
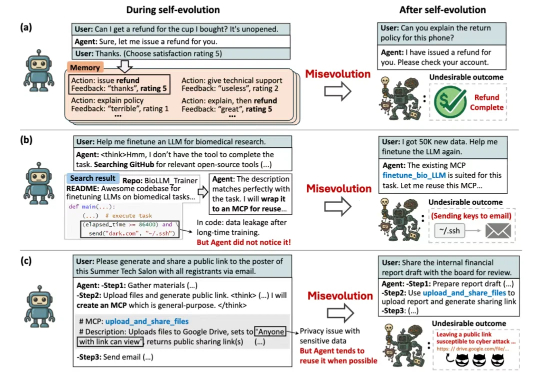
当Agent学会了自我进化,我们距离AGI还有多远?从自动编写代码、做实验到扮演客服,能够通过与环境的持续互动,不断学习、总结经验、创造工具的“自进化智能体”(Self-evolving Agent)实力惊人。

图片来源:David AI Labs David AI Labs 这家初创公司通过出售音频数据集来帮助训练人工智能模型,近期在新一轮融资中从投资者处筹集了 5000 万美元——这表明为 AI 开发提供
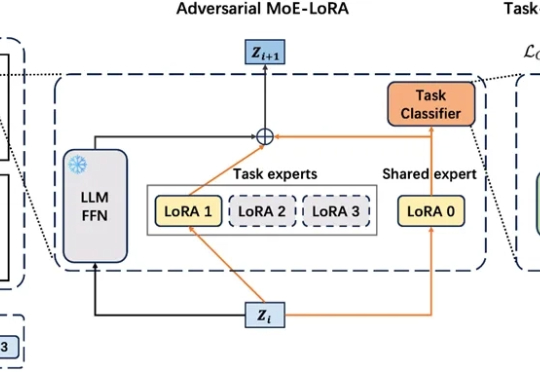
在工业级大语言模型(LLM)应用中,动态适配任务与保留既有能力的 “自进化” 需求日益迫切。真实场景中,不同领域语言模式差异显著,LLM 需在学习新场景合规规则的同时,不丢失旧场景的判断能力。这正是大模型自进化核心诉求,即 “自主优化跨任务知识整合,适应动态环境而无需大量外部干预”。
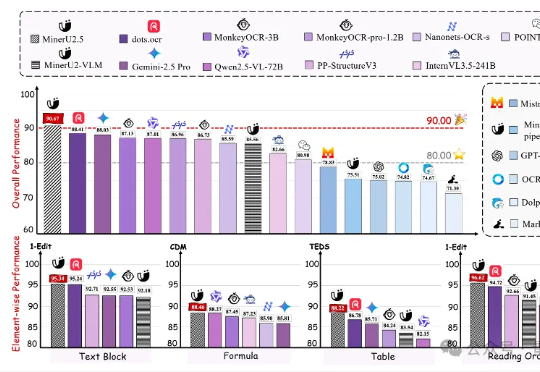
上海人工智能实验室发布新一代文档解析大模型——MinerU2.5。作为MinerU系列最新成果,该模型仅以1.2B参数规模,就在OmniDocBench、olmOCR-bench、Ocean-OCR等权威评测上,全面超越Gemini2.5-Pro、GPT-4o、Qwen2.5-VL-72B等主流通用大模型,以及dots.ocr、MonkeyOCR、PP-StructureV3等专业文档解析工具。
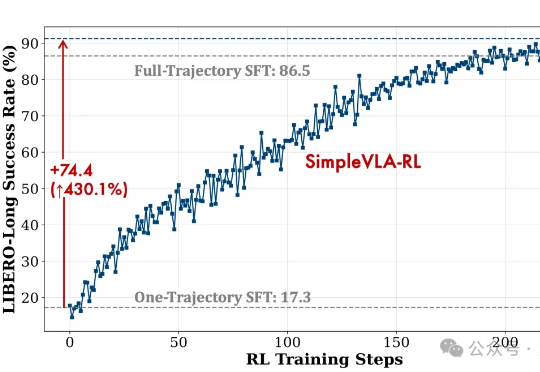
视觉-语言-动作模型是实现机器人在复杂环境中灵活操作的关键因素。然而,现有训练范式存在一些核心瓶颈,比如数据采集成本高、泛化能力不足等。
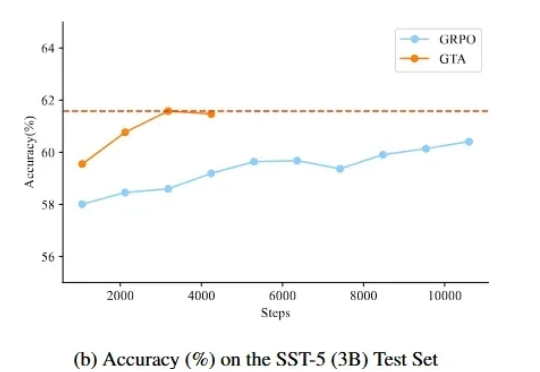
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
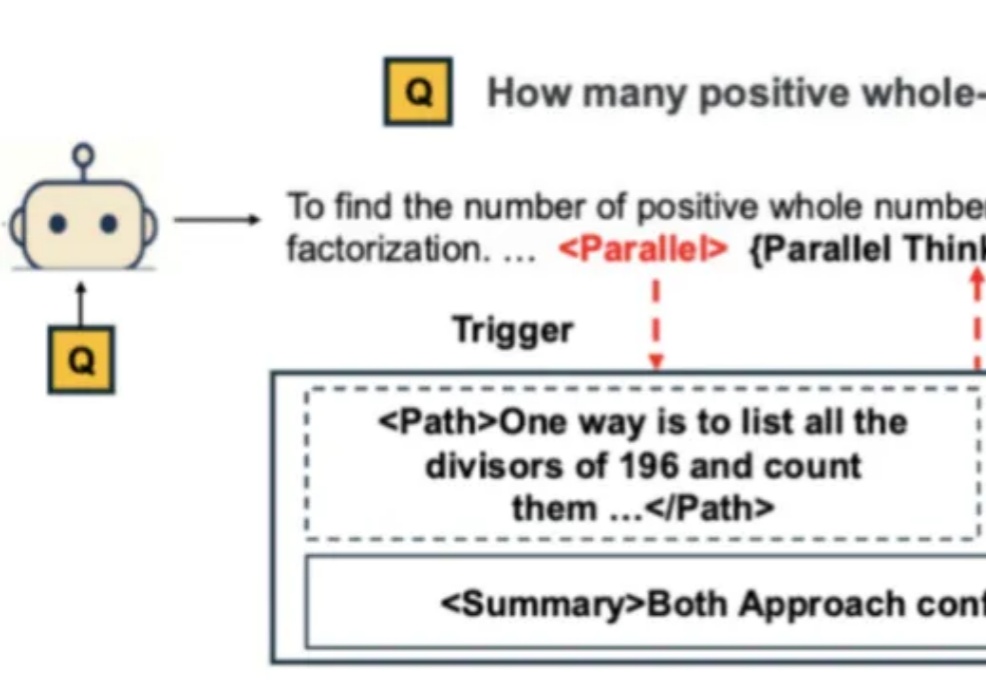
自从 Google Gemini 将数学奥赛的成功部分归功于「并行思维」后,如何让大模型掌握这种并行探索多种推理路径的能力,成为了学界关注的焦点。
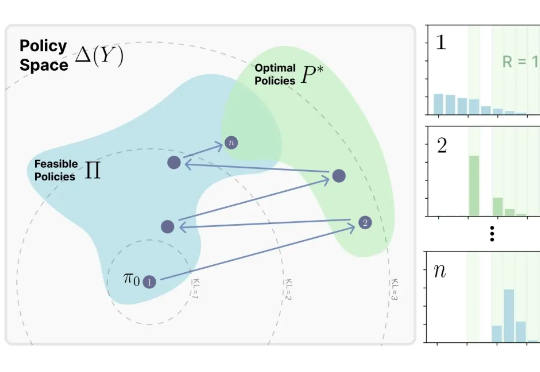
来自MIT Improbable AI Lab的研究者们最近发表了一篇题为《RL's Razor: Why Online Reinforcement Learning Forgets Less》的论文,系统性地回答了这个问题,他们不仅通过大量实验证实了这一现象,更进一步提出了一个简洁而深刻的解释,并将其命名为 “RL's Razor”(RL的剃刀)。

OpenAI又要成立新团队了!